My recent “Virtual List on Steroids” presentation at DIG-FM, and the preparation of a revised version to give at dotFMP next week, has prompted me to reconsider certain assumptions re: optimizing performance both locally, and across a LAN and/or WAN.

Specifically, there are two things we’re going to look at today. First, a way to dramatically speed up sorting on related data. Then, having incorporated that trick into the Fast Summary approach, we will compare Fast Summaries vs. Multi-Finds under various scenarios.
Demo files (structurally identical):
- Fast Summaries Re-revisited (80K records) [3 Mb compressed]
- Fast Summaries Re-revisited (640K records) [20 Mb compressed]
Sorting On A Related Field
In the smaller of the two demo files, we have 80,000 “order” (purchase order) records and we want to sort them alphabetically by vendor name, which lives in a related “vendor” table containing 1,500 records… and as you might surmise, these two tables are linked via a standard foreign-key-to-primary-key relationship, i.e.,
![]()
Here are field defs for the two tables:


To avoid skewed results due to caching, we’re going to close and then re-open the file between each sort. First let’s do the obvious, and sort our orders by the related vendor name like so:

It takes a glacial 12+ seconds on my aging Windows 7 laptop, and this is with the file running locally, not across a LAN or WAN… but that’s not particularly surprising since we’re asking FileMaker to sort 80,000 records on a related field (as opposed to sorting on a field in the same table).
Okay, let’s exit and restart the demo. Now what about the fast sort?

Don’t blink or you’ll miss it. The massive speed improvement is due to sorting on a local rather than on a related field… however… taking another look at field defs…
…we are not redundantly storing the vendor name, or any other de-normalized data, in the order table. So what the heck is going on?
Here’s the trick: sort on the foreign key (id_vendor) in the order table, but instead of doing a standard ascending sort, apply a custom order based on a value list called “vendor id and name”…

…which is defined like so:
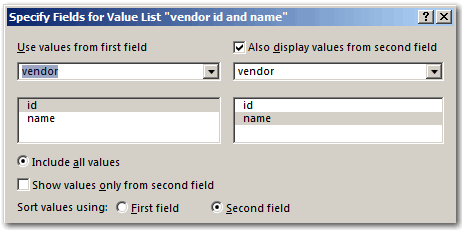
Bottom line: this simple trick enables “related data” sorts to run 10x faster.
Fast Summaries vs. Multi-Finds

Mikhail Edoshin’s “Fast Summary” technique has previously been the subject of two articles here on FileMaker Hacks, first in 2011 and then again in 2016…
- Fast Summaries
- Fast Summaries Revisited (introduces the Multi-Find technique)
Briefly, the two approaches work as follows:
Fast Summary (a.k.a. FS)
- Locate records in the Order table
- Sort by vendor id in the Order table (using the trick mentioned above)
- Loop through the found set stopping once on each unique vendor record, push summarized values into variables (using GetSummary)
- Aggregate the variables into a global text field
Multi-Find (a.k.a MF)
- Grab a list of vendor ids (sorted in vendor name order)
- Loop through this list, do a find in the Order table on each vendor id, and push summarized values into variables (values come directly from summary fields)
- Aggregate the variables into a global text field
As mentioned at the outset, the Fast Summary technique in today’s demos takes advantage of the custom value list sort trick, and is competitive with Multi-Find under the following test scenarios. Here are results from tests performed on a brand spanking new iMac, as well as on my aging Windows 7 laptop.

Note that on both platforms, Fast Summaries are a winner with server-side scripts. And if you decide to host the demo files on either FM Server or FM Cloud, you will be given the option to perform the script client side or server side.

(Unless you’re feeling masochistic, I don’t recommend running the reports client side when server side is an option.)
Looking at the above test results for FM Cloud, given that the reports are generated server side, you might wonder why they take so much longer than the local equivalents. The explanation is that there’s no free lunch when it comes to passing a large script result from the server back to the client across a WAN… the data is aggregated and assembled very quickly, but we have to wait for the script result before we can display it.
A Few Closing Thoughts
One thing I particularly like about Fast Summaries is that they can be used with any found set as a starting point (see Fast Summaries Revisited for more on this), whereas Multi-Finds require that you script your search criteria in advance. Fast Summaries are more flexible, as well as a bit less work to set up, and they perform better server-side if you can get away with sorting on same-table fields only.
Both of these techniques can be used to aggregate data for display using Virtual List, as well as a variety of other purposes (e.g., as part of a routine to generate JSON), and I recommend testing to see which is better suited to your current requirements.
Great tip…thanks for sharing Kevin!
This is timely for complex reporting I worked on today. Thanks!
Thanks Greg and Lisette. I appreciate you taking the time to comment.
Thanks, Kevin! Nicely explained! As usual.
Excellent work Kevin
Nice Kevin. Really appreciate your articles.
I must have been late to the party, but I’ve just read about your sorting trick for sorting with related data and am blown away, that is very very VERY awesome!
Thanks Daniel, I appreciate you saying so.
Thanks for the kind words folks.
Hi Kevin!
As ever real cool.
On the topic of „aggregating data into a global” did you catch my discovery that Insert Calculated Result can Concatenate strings in linear time? Try it out !
Hi Russell,
Thanks for saying so. I did check out your amazing discovery, and have already commented in that thread.
Best wishes,
Kevin
With regards to your suggestion that I give it at try, I haven’t found a good use case for it in my own work, or any of my FMH demos for that matter. I don’t tend to generate massive blocks of text via iterative appending… and iteratively constructed medium sized blocks, such as the ones in the demos accompanying this article (1505 lines/iterations), are too small to realize the performance benefit of your technique. Meanwhile, the demo accompanying your above-referenced Community posting makes it quite clear that under specific conditions it provides a massive performance boost, and I recommend that all FM developers check it out.
Actually, a few months after writing the above, I found a great use case — see tip #7 here: https://filemakerhacks.com/2018/12/30/tips-n-tricks-part-3/
About the sorting trick, I initially thought, WOW, but after looking into it I don’t really see the use for it. Doesn’t a stored lookup field in the orders table for the vendor name work equally fast and much simpler? If the technique could be applied the other way around on a one-to many relationship, then we would be talking … :)
The use of the trick is you don’t have to needlessly pollute your schema with a helper field.
Yeah, that’s a valid point, but you still have to make a new value list for any other field you might want to sort on. Not sure I think that’s preferable.
In reality this need doesn’t arise very often, for me at any rate. And if you work on live systems, as I sometimes do, you are always looking for tricks that don’t involve touching table schema.