Editor’s Note: Today I’m pleased to present a guest article by Jon Rosen featuring a creative and performant approach to removing duplicate records.
Recently, I had a situation where I had a found set of more than 500,000 records, but over ⅔ of them were duplicates. To remove the dupes, I initially went with the time-honored method I’ve been using for the last twenty years. I’ve been using it so long, that the original version used global fields because script variables hadn’t been created, yet. But now it seemed to run glacially slow on this large file.
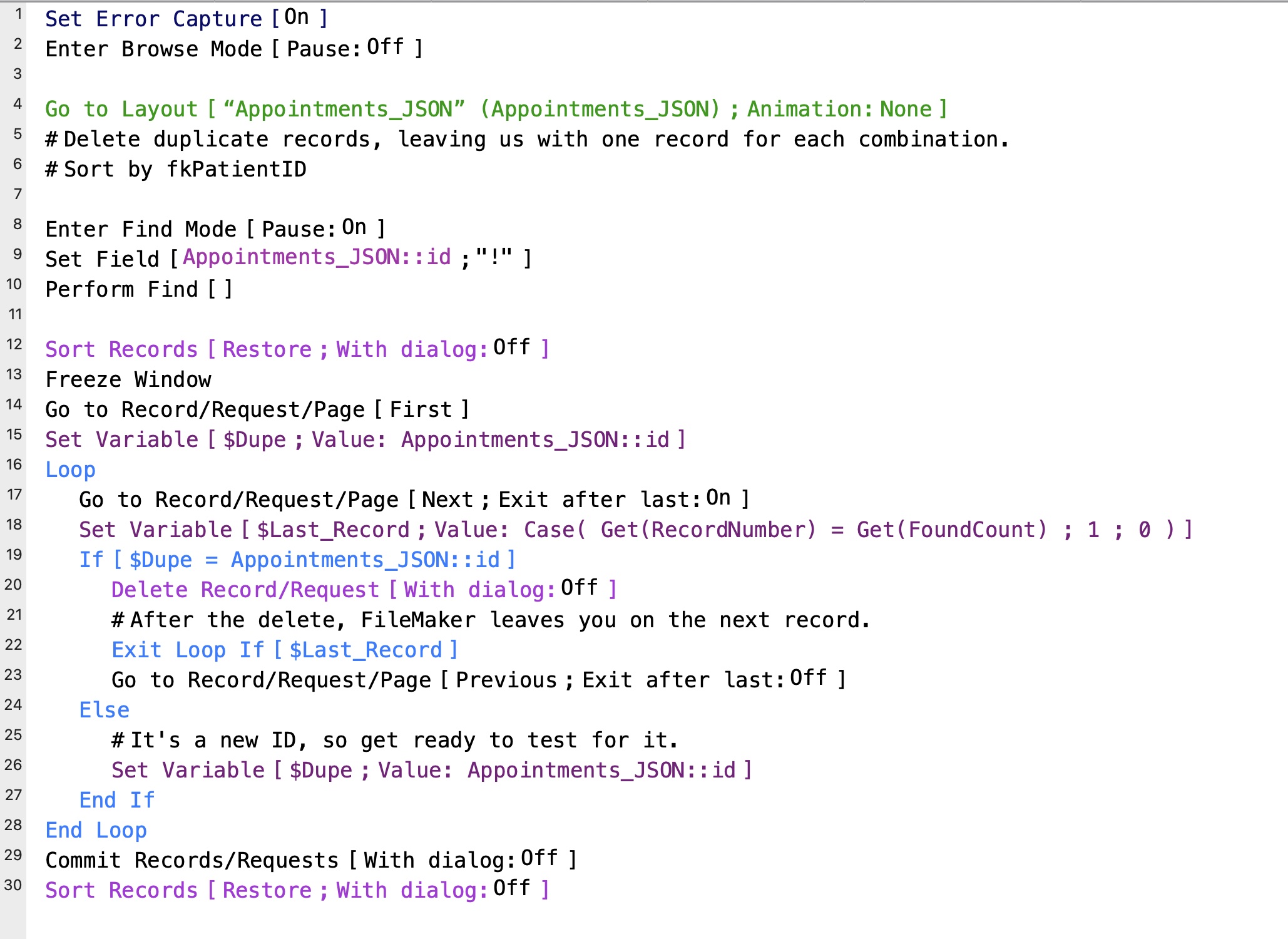
After giving it some thought, I came up with a new method of deleting duplicates that turned out to be simpler and many times faster than the older method. So, let’s start with a review of the original method. There’s a good chance you may be using it yourself.
Eliminate Duplicates (Old Method)