Editor’s Note: Today I’m pleased to present a guest article by Jon Rosen featuring a creative and performant approach to removing duplicate records.
Recently, I had a situation where I had a found set of more than 500,000 records, but over ⅔ of them were duplicates. To remove the dupes, I initially went with the time-honored method I’ve been using for the last twenty years. I’ve been using it so long, that the original version used global fields because script variables hadn’t been created, yet. But now it seemed to run glacially slow on this large file.
After giving it some thought, I came up with a new method of deleting duplicates that turned out to be simpler and many times faster than the older method. So, let’s start with a review of the original method. There’s a good chance you may be using it yourself.
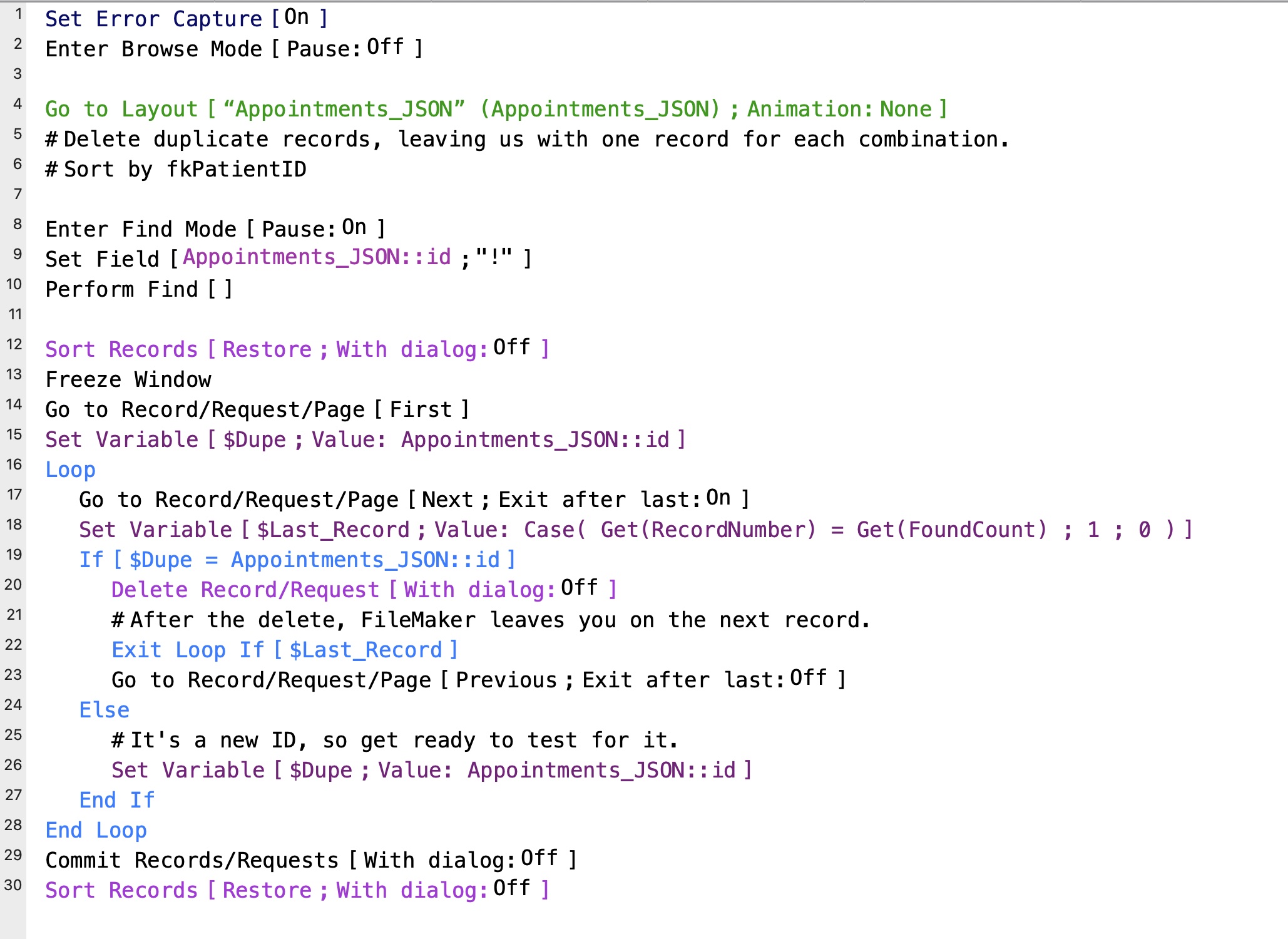
Eliminate Duplicates (Old Method)

Eliminate Duplicates (New Method)
Now for the new method. This is a summary of the technique:
1) Create a unique values list of the duplicate index field. I create a summary field of type list so I can get the unique values of the index field with a simple statement like UniqueValues ( table name::listIndex )
2) Find each index instance in a loop.
3) If you want to use the first instance, omit the first instance and then delete the remaining found set. If you want to use the most recent instance, Go to Last Record and omit it. Then delete the remaining found set. This deserves a little more discussion. If the records are true duplicates, you don’t care whether you keep the first or the last instance of the field. If, however, each new duplicate is a later version of that record, then you want to keep the last record. In this case, all you have to do is, after each find, Go to Last Record, omit it and delete the remaining records. If only one record is found, there is nothing to do.
This runs much, much faster than my old looping method. It is also a much simpler script, with fewer moving parts. And it works great with PSOS.
Here’s an example script. ListPatients is a List-type Summary field

About the author: Jon Rosen has been in the Claris FileMaker community for many years. He has worked both as an independent consultant and as an in-house developer for a number of organizations, and has presented at multiple DevCons. Outside the world of FileMaker, he enjoys playing bass guitar and collecting fountain pens. He and his wife live in San Jose, CA, the heart of Silicon Valley.
Jon. Can you quantify “much, much faster”.
Hi Stephen. The larger the record that needs to load, the bigger the difference. In my experience, you can expect it to run three times faster on average.
I like this method better than the original purely because it is easier to understand in terms of where you are in the loop process. Even though it’s still a loop, each loop iteration is only concerned with a single ID making it far easier to follow – great work!
Thank you, Daniel!
I am not a very experienced FMpro user.
In the script above, I struggle to figure out how to replicate “Set Variable I$listAppointments; Value: UniqueValues ( Appointments_JSON:: listID ) ]”
Is unique values a new command (I use FM15), or how do I get it. Also, what is the definition of “listID”?