Editor’s Note: Today I am pleased and honored to present the first in what I hope will become a series of articles by guest author Nick Lightbody of Deskspace Systems Ltd.
Summary: we will describe, discuss and illustrate the statistics that enable you to understand the why and how of FileMaker Server performance and suggest means of delivering a predictable and acceptable performance to your users.
Why this is important
FileMaker Server 13 is a wonderful and very reliable product, provided (as with any product) you recognise, understand and work within its limits.
However, Server is a binary product, in the sense that it either performs “good” or it performs “bad” — very slowly, but very reliably — as it grinds through its backlog until its load has reduced sufficiently for it to catch up on its queued calls and return to “good” mode.
The Deskspace server performance test shown in fig 1 illustrates a common scenario as the number of users increases and suddenly performance declines – dramatically.
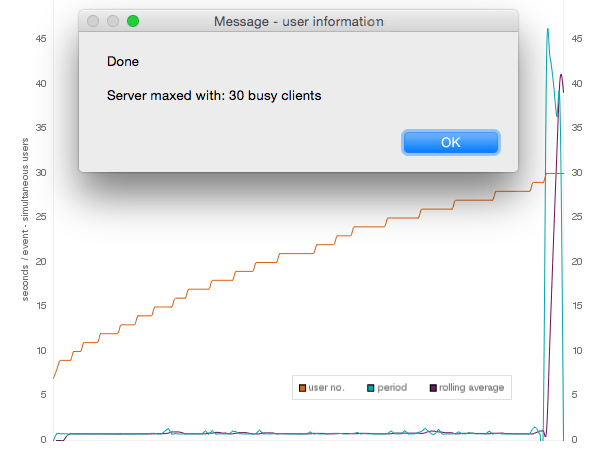
There really is very little middle ground, so when you look at the server statistics and watch the graph crawling along the floor — thinking that you are not really using its full capacity — you may in fact be deluding yourself, as we will illustrate. Continue reading “What is happening when FileMaker Server becomes overloaded (and how to avoid it)”
