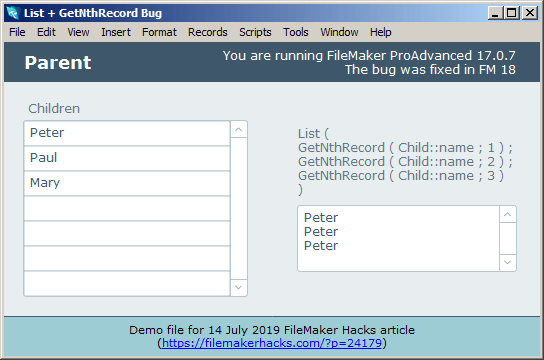
Recently I was working in FM 17 and ran into an unexpected bug. My use case was more complex than this, but the following bare bones demo illustrates the problem.
Demo file: List+GetNthRecordBug.zip
Recently I was working in FM 17 and ran into an unexpected bug. My use case was more complex than this, but the following bare bones demo illustrates the problem.
Demo file: List+GetNthRecordBug.zip
Today we’re going to take another look at a challenge we discussed last time (in Conditional Summary Report Header)… namely how to cajole FileMaker into displaying a subsummary, or a reasonable facsimile thereof, at the top of a report page when items in the group begin on an earlier page.

Demo file: Faux Subsummaries via JSON + Virtual List
 Continue reading “Faux Subsummaries via JSON + Virtual List”
Continue reading “Faux Subsummaries via JSON + Virtual List”
In part one, we explored various “anti-deduping” techniques. As you may recall, the challenge was to retain duplicates and omit unique entries from within an existing found set, as opposed to starting from all records… otherwise we could have just searched on ! (find all duplicates), but the ! operator does not play nicely with constrain, and cannot help us with this particular challenge.
Update 9 May 2015: it turns out that there is a way to reliably use contrain with the ! operator from within a found set — see Ralph Learmont’s technique + great demo + explanation here — Successfully Find Duplicate Values Within A Set Of Records
Also, last time, we were seeking to omit unique zip (postal) codes, which, in the example file, were always five digits long, i.e., of fixed length. Today our goal is to omit unique (a.k.a. “orphaned”) first names, and it turns out there are some additional challenges when the field in question is of variable length, which we will explore in today’s demo file: Anti-deduping, part 2.

Question: if we say we want to locate “all the Marias”, what do we really mean? Here are some possibilities… Continue reading “FM 13: Anti-deduping, part 2”
Recently there was a question about cleaning up a found set on one of the FileMaker discussion forums. When a question of this nature arises, it’s typically some variation on “How can I remove [or delete] duplicate entries?” But this was the opposite: For a given found set of customers, how can I omit those whose Zip codes only appear once in the found set?
In other words, keep the records whose Zips appear multiple times and banish the others.
Note that the challenge was starting from a subset of records. If the challenge had been for all records in the table, one could simply search on ! (find duplicate values) in the Zip code field. However, this trick won’t work when starting from a found set rather than all records. And constrain won’t help here because it doesn’t play nicely with the ! operator.
Update 9 May 2015: it turns out that there is a way to reliably use contrain with the ! operator from within a found set — see Ralph Learmont’s technique + great demo + explanation here — Successfully Find Duplicate Values Within A Set Of Records
Off the top of my head, I suggested…
Sort by Zip code, then loop through the found set from top to bottom… using GetNthRecord() test the current record’s Zip code against the previous record and also against the next record. If both tests are negative, omit, otherwise go to next record (and of course exit after last).
As it turned out, it was a one-time cleanup task, and my suggestion was good enough. But I had a nagging feeling there were better-performing ways to go about this, and today’s demo file, Anti-deduping, part 1, presents four different methods. I encourage you to download it, experiment, and add your own methods or variations… perhaps you’ll come up with a faster approach, in which case, needless to say, I hope you’ll post a comment at the end of this article.

Last October I began a series on Outer Joins, which explored a number of different ways to display summarized information in a grid, and at the time I concluded that the “fastest” method was to leverage the FileMaker relational model. And it was plenty fast, locally… and not too bad on a LAN… and technically, it was the fastest method on a WAN but only because the other methods we looked at were even dog-slower than it was.
I like to test solutions on a WAN, even if they’re only going to be deployed on a LAN, because it’s a great way to uncover performance bottlenecks. But recently I needed to deploy a summarized grid on a WAN, and was incentivised to come up with something faster… and after a bit (well, okay, a lot) of trial and error settled on the approach we’re going to look at today. To cut to the chase, with a million records in the test file, the previous best grid rendering time of 11 seconds on a WAN has been reduced by a factor of 10, to just over one second.

A while back I posted a technique to identify and count unique records. I recently discovered that while the technique is 100% reliable in terms of identifying unique records, under certain circumstances it will fail to count them correctly, due to what I believe is a bug in the way summary fields work. You can easily reproduce the bug by following the instructions in this demo file: broken summary field
Fortunately there are various ways to skin this particular cat, and today we’re going to look at one of them (demo file: broken summary field workaround).

The method for indentifying unique records hasn’t changed. Continue reading “Unique Records Revisited, part 1”
Demo file: 2010-11-21-count-unique.zip (requires FM 10 or later)
Yesterday we looked at a simple method to flag unique entries in a found set. This time, we’re going to look at an additional use for this technique, using the same data set and demo file as last time.
 As you may recall, we have a simple table of sales data, and previously we produced a summary report sorted by salesperson, but reordered by total sales, so that the top performing salespeople appeared at the top of the report.
As you may recall, we have a simple table of sales data, and previously we produced a summary report sorted by salesperson, but reordered by total sales, so that the top performing salespeople appeared at the top of the report.
[Update 15 May 2011: see this posting for additional information about this technique.]
Demo file: 2010-11-21-count-unique.zip (requires FM 10 or later)
 A question that comes up regularly on various FileMaker forums is some variation on “I have a table of sales data for my organization. For a given found set within that table, it’s easy to produce a report grouped by salesperson showing number of sales, total sales amount, etc…
A question that comes up regularly on various FileMaker forums is some variation on “I have a table of sales data for my organization. For a given found set within that table, it’s easy to produce a report grouped by salesperson showing number of sales, total sales amount, etc…

…and at the bottom of the report, I can easily display grand totals for number of sales and total sales amount…

