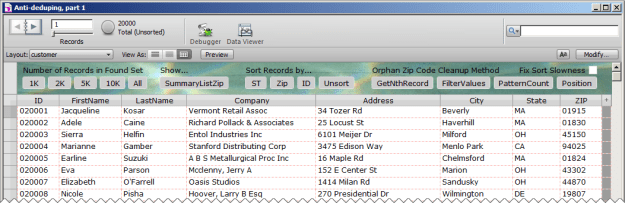
Recently there was a question about cleaning up a found set on one of the FileMaker discussion forums. When a question of this nature arises, it’s typically some variation on “How can I remove [or delete] duplicate entries?” But this was the opposite: For a given found set of customers, how can I omit those whose Zip codes only appear once in the found set?
In other words, keep the records whose Zips appear multiple times and banish the others.
Note that the challenge was starting from a subset of records. If the challenge had been for all records in the table, one could simply search on ! (find duplicate values) in the Zip code field. However, this trick won’t work when starting from a found set rather than all records. And constrain won’t help here because it doesn’t play nicely with the ! operator.
Update 9 May 2015: it turns out that there is a way to reliably use contrain with the ! operator from within a found set — see Ralph Learmont’s technique + great demo + explanation here — Successfully Find Duplicate Values Within A Set Of Records
Off the top of my head, I suggested…
Sort by Zip code, then loop through the found set from top to bottom… using GetNthRecord() test the current record’s Zip code against the previous record and also against the next record. If both tests are negative, omit, otherwise go to next record (and of course exit after last).
As it turned out, it was a one-time cleanup task, and my suggestion was good enough. But I had a nagging feeling there were better-performing ways to go about this, and today’s demo file, Anti-deduping, part 1, presents four different methods. I encourage you to download it, experiment, and add your own methods or variations… perhaps you’ll come up with a faster approach, in which case, needless to say, I hope you’ll post a comment at the end of this article.