Update 16 Sep 2024: JSONQuery 2.0 is now available.
Interview with Steve Senft-Herrera
[30 Nov 2021: Custom function and demo file have been updated. Some of the screen shots and example numbers referenced here in part 1 will deviate slightly from what you will find in the updated demo.]
Demo file: CF_JSONQuery_20211130_0120_PUBLIC.fmp12.zip

KF: Good afternoon, Steve. You’ve been developing JSONQuery over the last few years, and today I have the honor of presenting and discussing it here with you on FileMaker Hacks. I was wondering if you could start out with a brief description of what JSONQuery is?
SSH: Sure. JSONQuery is a custom function, and it operates on JSON. Typically you’re going to be feeding it a large JSON array you’ve received back from the FileMaker Data API, or somebody else’s API, where each record is a JSON object within a larger parent JSON array, and the purpose of this function is to be able to find child elements in that parent array that match certain criteria and return just those elements to you.
Above and beyond that it has a lot of bells and whistles, some of which I’m sure we’ll cover, but the main impetus for writing it was giving you an easy and fast way to essentially query a JSON array.
For example, let’s say you have an array filled with a lot of orders, but you only need to get the order items that are being shipped to a certain city, or to a certain state, then this function would allow you to easily obtain those elements in an efficient manner.
KF: And of course FileMaker has built-in JSON functions, but sometimes there isn’t an obvious way to accomplish the particular challenge we’re faced with. So, would this be a good time to take a tour of your example file?
SSH: Yes, but I’d like to back up for just a moment and say that anything you can do with this function, you could instead do by writing your own While loop to cruise through all of the entries in your JSON array and find the correct ones.
Part of what I think this custom function offers as an advantage over writing your own While loop is A. it saves you the time of writing and debugging that routine on your own, and B. it has sort of a little bit of special sauce that that will operate faster than just iterating through every single element until you find all of your matches. It will perform more efficiently than that approach.
KF: This might be a good time to mention that since you do make use of While under the hood, the minimum version of FileMaker required to run JSONQuery is 18.
SSH: That’s correct, yes, and while we’re talking about versions, if you want the support for being able to work with JSON that uses dot characters within the keys then you’re going to need FileMaker 19.3 or later to take advantage of bracket notation.
[Editor’s note: for more information see Working With The JSON Functions in the Claris online help.]
SSH: If you’re running an earlier version than that you’ll still be able to do all the same functionality, but you just won’t be able to do it when your input has keys with embedded dots.
KF: Got it.
SSH: So yeah good point to bring up the versions there.
KF: Okay, let’s dive into your demo file. I really like the way you’ve set up the Examples tab.

KF: The examples are in a portal, which is filtered by the popup menu at the top right of the screen.

KF: To access a specific example you click a row… and why don’t you take it from here?

SSH: Sure. This is the example detail layout and it contains several sections.

SSH: In the upper left corner is a sample calculation that illustrates how you might use JSONQuery. I’ll explain what that query is doing in just a moment.

SSH: To the right of that is a field that contains sample JSON input to illustrate a variety of different examples; there are a few different versions of this JSON that we can use, but for now suffice it to say that we’re looking at a basic array filled with elements and each element contains something about a person, whether it’s their address, or the automobile that they own, etc.
The UI for this will allow you to select different types of sample JSON so we can try out different queries but for now we’ll just stick with something simple, which is this array of 250 items.

SSH: Bottom left of the screen is the place where I try to give some human explanation for what’s going on, so that you can have an easier time learning it, instead of just staring at the example and trying to make sense of it with no explanation at all.

SSH: And the bottom right pane is where the result of the calculation appears. You can see, I just cleared it here by clicking this little circle arrow icon.

SSH: And so let’s talk a little bit about this example and then we can we can also go into a couple more features of this UI, but that pretty much covers the basics. This is an example of using JSONQuery to query this sample JSON here, represented by “JSON” in the first parameter.
SSH: What this example is saying is, take the JSON, look for the key named “id” and when it’s equal to 247 return the results. JSONNumber is telling it that this “id” field has a value of data type of number; you have to sort of tip off JSONQuery as to what what the data type is for your query to help it find the value. So let’s go ahead and run it with this button in the upper right.
![]()
SSH: And indeed we’re looking at this one record here.

SSH: As an example, since we just returned one record, let’s modify our input and change the ID on one of these other records to 247.

SSH: Because I’ve changed the input I’m expecting two records to come out of that, so let’s rerun the example, and now I’ve got two records, the one that I doctored up as well as the original one, returned as an array.

SSH: If I enter a non-existent comparison value and then run it, I get an empty array as a result, telling me that no records matched that ID.

KF: Is that because we started with an array for the input, or is that just the way JSONQuery works?
SSH: For basic usage it is going to return you an array of matches, and when there are no results, an empty array. There are nuance cases where it could return a single value or an object, and then some very advanced cases that allow you to do transformations which could result in returning all kinds of things, for example: a list of data, an array, or an object, but for basic usage it is going to return you an array of matches.
KF: For a long time I’ve been wishing I could use a SQL-like language to query JSON directly, as opposed to having to first parse that JSON into FileMaker records, and it looks like that wish is finally coming true.
Let’s review what just happened: We started with an array with 250 objects, each object representing a person record and some child data associated with that person. You then instructed JSONQuery to reach into that pool of 250 records, which isn’t huge but isn’t trivial either, and extract just the objects that match ID on 247… and boom it returned them in a split second. So, within reason it’s very fast.
SSH: That’s a really helpful comment that you just made for a couple of reasons. The first is the mention of SQL. One of the things that I tried to do with JSONQuery was to use terminology that would be familiar to contemporary FileMaker developers… we’re now somewhat familiar with, or possibly well-versed in, SQL, in JSON, and in Javascript. It’s not that I wanted to deliberately use SQL syntax with this function but I found it actually convenient to do so because I knew that people would be familiar with it.
So while this operator is named EQUALS, there’s also an operator that we’ll look at a little later on called LIKE which somewhat resembles a LIKE match in SQL, so I when I could I borrowed nomenclature that would be familiar from SQL or from FileMaker. A bit later we’ll see there are some aggregate functions that use function names that are mostly the same as in FileMaker, whether it’s LIST, SUM, AVG, or COUNT or something like that.
KF: There’s also MIN and MAX right?
SSH: Indeed, and those are thanks to you, based on our previous discussions. You were the one who inspired me to add those so you get to take some credit for the fact that those are those are in this function.
KF: I was not shy about communicating my wish list.
SSH: Those were good ones to add. I think it would have been incomplete without them. But jumping back to what you said a moment ago about operating on 250 records in this example and it being very fast. You can definitely use this function on sets of data that that are small, like 250 records, and it’s going to work great for you.
As you get to the larger record sizes, then you’re going to find one of two things. If you’re trying to process a lot of the nodes in your JSON then it could be that it’s too slow for you, unless you’ve you can afford to have your code run slowly for that moment. However the function is designed to still perform very well with a large input if you’re just trying to find that needle in a haystack.
So if you’re basically just looking to find one or maybe two or three target records, out of a list of, say, 1000 or even several thousand records, it will still perform well, and I want to see if we can do, an example of that right here. We started with 250 records… let’s bump it up to the next level of sampling which is 1000 records, so we’ve got four times the amount of data.

SSH: And let’s just go ahead and find one record, in this case where the ID is equal to 420, and my assertion is that this will still be a pretty quick operation, despite having quadrupled the data input size.

Okay, we ran it and it’s still very fast, just over half a second on my machine which is not a speed demon of a machine. So the point is that, as the input size increases, it’s still performant for just finding that one or two sort of needles in a haystack.
Now if you need to find a whole bunch of records, you will find that the performance slows down so let’s do an example to illustrate this. Instead of finding on an ID let’s beef up the example and instead of matching just on a single flat key we’re going to match on a JSON path, “address.state”.
KF: And it is case sensitive.
SSH: It is case sensitive indeed. We could illustrate that but I think everybody’s probably willing to trust that if I botch the case here we’re not going to find anything. Anyhow, let’s find “address.state” equal to NY for New York, and it’s no longer JSONNumber that we’re matching on so I have to change the ValueType to JSONString and we’re going to keep it at 1000 records and we’ll run the example.

SSH: And we got back 66 records and now we’re looking at about three quarters of a second so still not too bad. I was actually expecting it to take a little bit longer so let’s make it a little tougher and illustrate something else — instead of the EQUALS operator we’re going to use the IN operator.
Again this is a good example of borrowing nomenclature from SQL, and IN will allow me to supply a return-limited list of several values, so instead of just New York, let’s also find California, Wyoming, Rhode Island and Oregon.

KF: I might point out that, as a Mac user, you were able to enter the pilcrows from the keyboard via Option-7.
SSH: Yeah I was being lazy. We could just as well embed a List function in here, in fact there’s something I like about doing it this way with List. I feel like it sort of illustrates the values better.

KF: And that’s an additional thing you can do that we haven’t seen yet with this custom function, right? Because before you entered a static string, but now it’s an embedded formula.
SSH: And indeed it is. In this particular example that we’ve cooked up here we’re saying return me all elements that have a state value that is among one of these listed here in this next parameter. And we’re still leaving this as JSONString because we’re operating against the field which is data type string, and let’s see what we get.

SSH: This time it took about 2.3 seconds and we returned 197 records out of 1000 so you get the idea that the more records you’re returning the longer it’s going to take, and the reason I’m calling this out so much is I want people to have an understanding of when they might reach for this function and when they wouldn’t reach for this function, and I would say, when you know that you just need to handpick a couple of values then you can you can have the input size be rather large and still get the performance out of this.
On the other hand, if you know you’re going to be picking whole bunch of values out of your input then you’re probably going to be happier if your input is limited to smaller sizes, like 250 records or 500 records or something like that. But in any case it’s not like you have to limit it down to something super small — you know this is this function is not about just operating on 10 or 20 records, you know it’s definitely built to be able to handle at least several hundred records.
KF: This is amazing. What are you going to show us next?
SSH: Okay what I think I’ll show next is, in the example we just looked at, we’re returning all of the all of the elements that match, but let’s say we wanted to just get part of those elements, maybe we want say to JSONQuery, match these elements, but please just return what you find at one particular path. So let’s say we just wanted to get the company name where they work, we’ll supply a result path to that which will be “work.company_name”.
Now when we run, this is still going to find the same 197 records, but it’s going to just return this one facet of these records.

SSH: And this time it took a little bit longer, about 2.6 seconds, but you can see, here we have an array with 197 entries and it’s just the company name. So this allows us to zero in on just one particular attribute that we care about.
And as a variation on that example, instead of a single string for every element, we can also return substructures… so let’s say we want to return addresses. In this case I would put a result path of “address” because that’s the key that it’s under, and it’ll do the same 197 matches, but in this case it’ll return just the address substructure for each of these.
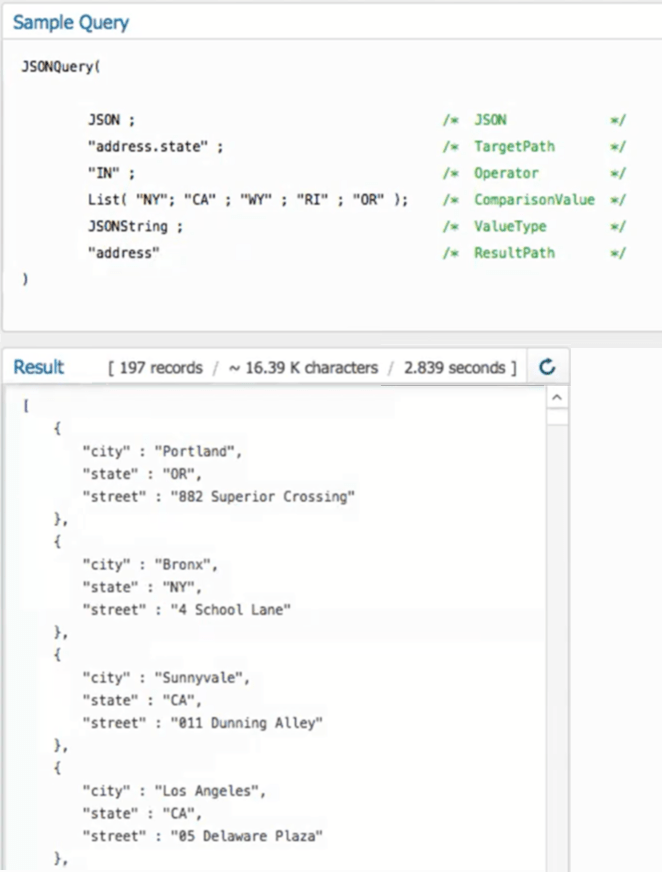
KF: Nice.
SSH: Next I’d like to talk about a couple of the aggregate functions. Let’s take a look at extracting a particular numeric value… let’s pull out just the “lucky number” for these 197 records…

SSH: …and the path for that would be “person.favorites.lucky_number” which we can enter as the result path argument. And when we click the “run” button we get a big list of lucky numbers in the form of an array.

SSH: What i’d like to do with this is show a couple of the aggregate functions that we can use, and these aggregate functions are very similar to the ones we use in FileMaker: we’ve got SUM, COUNT, AVG, MIN and MAX that allow us to operate on a list of data, like the results that we’re seeing here, and aggregate those respective values, whether it’s the sum, or the count, and so forth.
Let’s start with something easy, let’s use the COUNT operator, which is one of the aggregate operators supported by JSONQuery. We’re going to wrap our result path in a function call like this, and in this case, we already know there are 197 records so I’m expecting to find 197 as a result, when we run this particular group.

SSH: It takes about the same amount of time that it took to find all those records, and just to confirm, we did get a result of 197.
Next let’s change from COUNT to a different aggregate operator in the result path, let’s ask for the SUM instead…

SSH: And we’ve got 9539. We could do an average and that would look like this.

SSH: Let’s let’s do Min and Max real quick. Min is zero…

SSH: …and Max is 101…

SSH: …and again it’s taking a while because we’re kind of at the upper end of where things are still comfortable to us but starting to realize that it does take its time when when you’ve got more data that you’re having to plow through.
KF: But let’s put that into perspective. To transform this JSON to a point where you could run something faster than this query would be time consuming, both in terms of development time, but very likely in terms of run time as well.
SSH: I think you’re right, and I’m trying to be very objective or pseudo objective here. My hope with presenting this function to people is to make it clear enough what it does and doesn’t to so that people can decide for themselves if they want to use it, and hopefully they’ll check it out and find out some of the advanced things that it can do, which we might not get into today, or we might only touch upon a little bit.
Quite honestly I think it’ll be a balance between whether you’re comfortable using somebody else’s elaborate function, and question number two is how long would it take you to write code that would do the same sort of thing. If you’ve already got something that’s ready to go well, then you’ve got a couple options now, but if it’s something that would take you a good amount of time to write, and test, and make sure that it’s working, then you’re starting to get to the point where using this function is advantageous to you.
And then, if you’ve got some massive amount of data that’s just going to overwhelm this function you’re probably going to do something like punt to Javascript. On the other hand, if you’re in the middle ground and you know you could use Javascript or this function, you might find that you’re trying to do it server side and you can’t use a web viewer and you don’t want to use a plugin and so that’s where again this this sort of function starts to show some of its value.
KF: Well stated. And returning to a comment I made a moment ago, even if you already had the routine written, you’d spend time waiting while the routine parses your JSON into records in multiple related tables, just so you could “query it quickly” in FileMaker.
SSH: Yeah, there are a lot of considerations, I think. You know, originally it was all about just finding a needle in a haystack because I had a friend who was getting a large amount of JSON back from the Data API, he needed to find that one target record in the result output that matched a certain criteria, and he found that it took a very long time to loop through and find that record. The iteration was just killing the performance. And that was a motivation for writing this particular function, because, while it does include some iteration it doesn’t strictly rely upon iteration to find that needle in the haystack — it has its ways of doing the seeking a bit more efficiently.
KF: Funny you should mention the Data API because the tipping point for me deciding to get in touch with you was that I needed to analyze some data that was coming back from the Execute FileMaker Data API script step, and realized if I had JSONQuery I could get what I wanted directly, vs. writing a routine to walk and parse the JSON nodes.
Now that we have the aforementioned script step, which runs internally within FileMaker, those of us who have managed to dodge the JSON bullet up to this point, are going to be increasingly confronted with results structured as JSON. And the next step is going to be to say, “Okay I’m looking at a bunch of JSON… how do I quickly locate and extract just the information I care about?” and I think that’s a sweet spot for JSONQuery.
SSH: Yeah I think so, and it was the Data API that inspired me to write the second version of this function, because, as you know, this function originally was released shortly after FileMaker 16 came out. I wrote this function as a response to what I saw my friend going through, querying data and trying to pick out that needle in the haystack from the Data API result.
When you reached out to me several months ago, I had sort of started a second version of JSONQuery that had some more advanced capabilities, but I basically left that on the shelf. It was when you reached out to me and we started talking that I began thinking, hey, maybe people could have a use for this. That’s what inspired me to finish off this version, and this version does require FM 18. The original version just required version 16, but version 2 that we’re looking at now requires FileMaker 18 or later.
And it has it has some some advanced capabilities which were motivated by the Data API. I’m trying to think whether I’m skipping ahead too much by showing some of these, but I think it’s probably a good time to do that.
KF: Sounds good to me.
SSH: Okay, so as a backdrop, I was thinking about what sort of results we might get back from Execute FM Data API or from the Data API itself. And, in particular, I was concerned with cases where you have portal data on the target layout and so in your API results you’re not just getting an array that contains a bunch of very flat objects, but also arrays of related children, and the first version of JSONQuery wasn’t able to deal with that.
So the idea here was let’s say we have a data set that has keys of regular data but also contains keys that have arrays of child elements, and I’m just going to grab one element, and then we can look at it in a text editor it’ll be a little easier than if I try to scroll through it and show it to you.
This example is based on having a software consulting company, and we’re looking at one single object, that contains an array of objects with contact information for each account rep.

SSH: It contains an object of client data, including objects nested within other objects,

SSH: …and it contains another array under the projects key, which is an array of projects. If we look at one project to start with, we can see a project contains developers and it contains hours billed, percent complete, project name, status, and so forth, so it’s a very rich structure.

Also one of the properties of the developer is an array of skills.
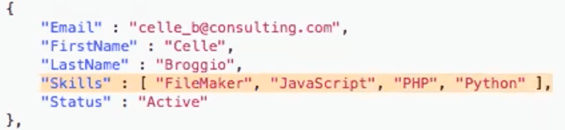
So we’ve got arrays within objects that are within arrays that are within objects that are within a child object, all of which are inside of one giant array of all these elements. So fairly rich, and in fact this example I think is richer than anything we get back out of the Data API.
KF: We’ve got parents, children, and grandchildren represented here.
SSH: Exactly. So, bringing this back to JSONQuery, I wanted to include functionality to be able to query based on, not just the parents, but their children, their grandchildren, and so forth.
In this example, bearing in mind AccountReps is like a portal, it’s got several reps in an array, we’re saying, “Within AccountReps match me any rep that has a first name of Tomkin”. That’s what this particular path is telling us here, it’s saying go to AccountReps, match against any item in that array and choose the first name.

SSH: Just in case it makes things a little bit more understandable, I could have used a number in place of the [*], I could have put in [0], and that would have told JSONQuery, hey go to AccountReps and go to the “zeroth”, which as you know for humans is the first entry in this array, and if it has a first name of Tomkin, match it.
At any rate, one of the advanced features of this new version of JSONQuery is the ability to use a [*], and that allows you to perform searches against related data.
Let’s try an operator we haven’t used yet… we’ll use the LIKE operator, which is a “begins with” type of matching. This is a cool one. Let’s start out simple and then build it up. In this case, we’re saying look through the JSON, check every item in AccountReps and if the email begins with “pa” then consider it a match, so let’s return those…

SSH: …and it looks like there are five matches. Right now we’re returning the entire object, but I’m going to introduce dot slash notation here…

SSH: …and dot slash notation in the result path is specifically tied to cases where you are using a wild card in your target path.
What you’re saying is, once you’ve found matches, don’t return me the entire object, but instead cut it off and just return everything from the AccountReps node onward. I don’t want the entire object, I just want the AccountReps.

SSH: So now, you can see, we’re returning just the little sub-portion that we queried, and that’s courtesy of this dot slash notation. We can also extend it by adding a field name so let’s say I just want the last name, I can do that by inserting “LastName” at this point, so the dot slash is saying, find the matching nodes of AccountReps, and then of those, just return the last name.

KF: And indeed it does. You’ve been sort of cavalierly making changes to your demo as you go along. Is there a way to undo changes, in case people want to be adventurous, but are afraid of trashing the demo?
SSH: Good point. It’s quite possible that, after experimentation, you may want to restore the original example, which you can do by clicking this circle arrow here.

KF: Are you resetting the query only, or…?
SSH: It will reset the entire example and bring it back to the original state as it shipped with this file. So you can edit things to your heart’s content and then when you decide to you’ve had enough of that, hitting this button will reset both the sample query and also the choice of the input back to the original selection.
KF: And I see that you’ve also provided a way to reset all examples at one shot like so:

KF: Would this be a good time to look at an array example I wanted to ask you about?
SSH: I think it would be great.
KF: Okay, thanks. I’m going to open this up in a little utility file I threw together. As you know, FileMaker has a nice built-in function, JSONGetElement, which among other things can extract a row in a two dimensional array, but there isn’t a corresponding function to extract a column.

KF: When I see a structure like this, I envision it as a spreadsheet with five rows and nine columns. JSONGetElement can address the horizontal aspect, but I’m curious how we could use JSONQuery to address the vertical aspect, for example, to extract just column two?

SSH: Okay let’s take it argument by argument.

“Json” obviously represents your source JSON, and in this case you can leave TargetPath empty.
You’re going to set Operator to MATCH_ALL, which means ComparisonValue will also be empty. As its name implies, MATCH_ALL considers everything a match, so it’s not going to have to worry about performing a comparison.
For ValueType, JSONNumber is accurate, but it’s okay to leave that empty as well. And, finally, the ResultPath is where you’re going to type in the address of what you want. Since you want the second column, and since JSON uses zero-based indexes, you’re going to type in a 1 surrounded by array brackets.

KF: Amazing.
SSH: Basically you told JSONQuery to go through every element, and pull out the value at the path you specified, in this case array items at index position 1.
KF: That’s really something, and again it’s not that we couldn’t accomplish this using the While function or some other methodology, but this is lightning quick and very intuitive.
SSH: Basically under the hood, it is using While, but you didn’t have to write and debug the While statement. You had to install this function, and get familiar with the syntax… which, the more you work with it, the easier it gets.
KF: That’s definitely been my experience. I have another example, I’d like to look at. This is a simplified version of a real world challenge I had recently, and I used JSONQuery to solve it.
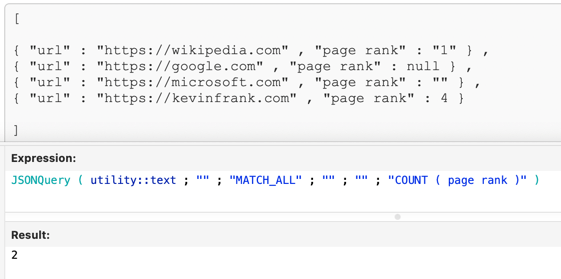
As you may know, there are services out there where you can feed them URLs and search terms, and those services will return JSON containing the Google page rank for each URL and search term. In this example, I didn’t include the search terms and I made up the results, but at any rate, the challenge was to reach into a particular set of results get the average value of the page ranks.

KF: In this example 1 + 2 + 3 + 4 equals 10 divided by 4 equals 2.5, so we know what we should get back. The reason I chose to use JSONQuery to get that average was because I wasn’t looking at a canned example with just four entries, but a JSON array with hundreds of entries. Rather than me attempting to blunder my way through an explanation, would you mind telling us how you would go about it?
SSH: Sure. So the the way that I would approach this is I already know I’m going to use MATCH_ALL because I know I want to operate on every item in the array. Next I like to fill in the result path, so “page rank” is what I would put in there. And if you run just that query there, it will return you an array of all the page rank values.

KF: Got it.
SSH: And this time, instead of just putting “page rank” in that last parameter, let’s surround it with the AVG aggregate function.

KF: Beautiful.
SSH: Yes. There you have it. Those are actually great examples, and you know, there are some nuances that that I’ll just mention since we’re looking at AVG if you if you don’t mind doctoring up your example.
Notice that all of those page rank values are stored as JSON strings.
KF: You can tell because they’re surrounded by quotation marks.
SSH: Yes. JSONQuery has no problem with that at all, but let’s just say, for instance, that some of them are stored as strings and some of them are stored as numbers.
KF: Okay, let’s remove the quotes from two of the entries so that JSON considers them to be numbers rather than strings.

SSH: The AVG function is still going to catch all of those but there’s a variation on this I’d like to show.
KF: Please do.
SSH: Okay, the variation is, if, instead of using AVG we use AVG#, JSONQuery will operate on numeric values only and ignore the strings.
KF: So, in this case the 2 and the 4 are now numbers, and if we click Evaluate…

KF: …what it did was (2+4) / 2 = 3.
SSH: Yeah. I think this could be a very nuanced thing for people, but if you’ve got a data set where some values are strings and some values are numbers, and you don’t want to include the strings, use AVG#, and that’s your way of telling the aggregate function, “Hey just operate on the numeric values”.
This had a lot of your input into it, because I remember, we talked about this one day, and you very wisely said that the default behavior should be a similar to, if not exactly the same as FileMaker’s behavior, so that people get something that they’re familiar with.
And then, if you have some variations on that, they can be the special cases… so without the pound sign it’s basically what FileMaker would do: take everything there and if it’s a string it’s going to implicitly wrap it in GetAsNumber, and then do the average based on all those values.
KF: And, if I recall correctly, you’ve got the same functionality for COUNT and SUM also?
SSH: Yeah… for COUNT it’s actually a little bit more advanced, but you’re correct for SUM, MIN, MAX and AVG: all of those have the ability to append a pound character to say whether or not you want to limit it to just the numeric values.
I think we should try COUNT out here, because it’s kind of an interesting little beast; it’s got more possibilities to it.
KF: Okay we’re going to replace AVG with COUNT, so we’ll do a plain vanilla COUNT on the page rank, and I would expect to get back 4.
SSH: I would too.
KF: I’m also using "" instead of JSONNumber for the ValueType argument, since you said it was okay to do that.

SSH: Okay now COUNT allows for an extra parameter, and the parameter is separated from your field name with a semicolon. The extra parameter tells it what kind of values you want to count, so let’s say you enter NUMBER.
Now, when you run that you’re telling JSONQuery that it should only count numbers.

KF: Sweet.
SSH: And you can enter a space- or a comma-delimited list there to include multiple different types, for example, if you enter NUMBER STRING then you’re going to get back both your number and your string values.

SSH: Basically it gives you the control over what kind of things you want to count, and where this could come in handy is maybe you don’t want to count null values, or maybe you do want to count null values. Maybe you want to count empty values, and maybe you don’t.
KF: Okay, I’ve changed the example to have a number, a null, an empty string, and a non-empty string.
KF: And just confirming that your implementation of COUNT (without any special arguments) mirrors the standard FileMaker behavior for that function, which is to say that only populated values are counted.
What if I want to count just the nulls (or in this case, null, singular)?

SSH: It’s going to return 1 because once you start using the extra parameter you have to specify everything you’re looking for.
KF: That is what I wanted. What if I want to count the "" entry as well as the null?
SSH: Type a space after the NULL and then put EMPTY_STRING.

KF: Is there a list of all the extra parameters for COUNT?
SSH: Yes, here it is:
NUMBER
BOOLEAN
FALSE
TRUE
STRING
EMPTY_STRING
NON_EMPTY_STRING
NULL
ARRAY
OBJECT
ALL
SSH: And note that last one — if you want to count everything you can use ALL.

SSH: These are all documented in the file. Basically, as you said, COUNT without that extra parameter, behaves like the FileMaker function. If you need more control that’s when you break out the extra parameter, and you start specifying what it is that you want to count.
[To be continued…]
Steve Senft-Herrera has been developing using FileMaker Pro since 1994. He started working at Beezwax Datatools in 2015, and he credits the collaborative and immensely talented team at Beezwax as being an inspiration to learn and grow every day. Outside of the world of FileMaker, he enjoys cycling, music, being around animals, and being silly.
This looks amazing. I have admittedly not read everything yet. My current challenge with JSON is to both find then update a certain object in an array (update it back in the original full json, not just what was found). Is there a way to do that with this function? For example
could I find id 44, update the ShipmentType to “USPS” and return the full JSON back with it updated?
{
“Shipments”: [
{
“id”: 23,
“ShipmentType”: “UPS”
},
{
“id”: 44,
“ShipmentType”: “Fedex”
}
]
}
Hi Ben,
I asked Steve Senft-Herrera about this and he indicated that what you’re asking for (supply a value, get back the index position) can be done via JQ but it’s a bit convoluted, so he suggested installing and using this “helper” CF.
Kevin
================================================================
ReturnArrayIndices( JSON ; TargetPath ; Operator ; MatchValue ; ValueType )
—— Function Body ——-
Let([
_TRANSFORM = “{\”MAP\”:[{ \”SOURCE\”: \”.index.\”, \”OUTPUT\”: \”INDEX\” }]}” ;
~array_indices = JSONQuery( JSON ; TargetPath ; Operator ; MatchValue ; ValueType ; _TRANSFORM )
];
JSONQuery( ~array_indices ; “” ; “MATCH_ALL” ; “” ; “” ; “LIST( INDEX )” )
)
I just tested in my sandbox file, and here are the results.
Thank you and Steve! That works wonderfully.
You are welcome Ben. That was a great question you asked. Also see the first comment on part 2 of this interview.
My mind is blown – absolutely stunning!
Thanks Daniel. I feel the same way.
This is amazing. One question, can you use variables in ComparisonValue section? I keep getting no values returned.
Hi Scott, it should work fine. Can you share sample JSON and details re: what you’re trying to accomplish?
I just read the second article and saw how to search for Dates, that was the missing piece. it’s working now. thanks for the quick reply!