Introduction
From time to time FileMaker developers are tasked with generating Excel spreadsheet output. There are a variety of ways to accomplish this, in some cases via native FileMaker commands (Export, Save/Send Records), and in other cases using various workaround methods — some of which have appeared on this site in years past.
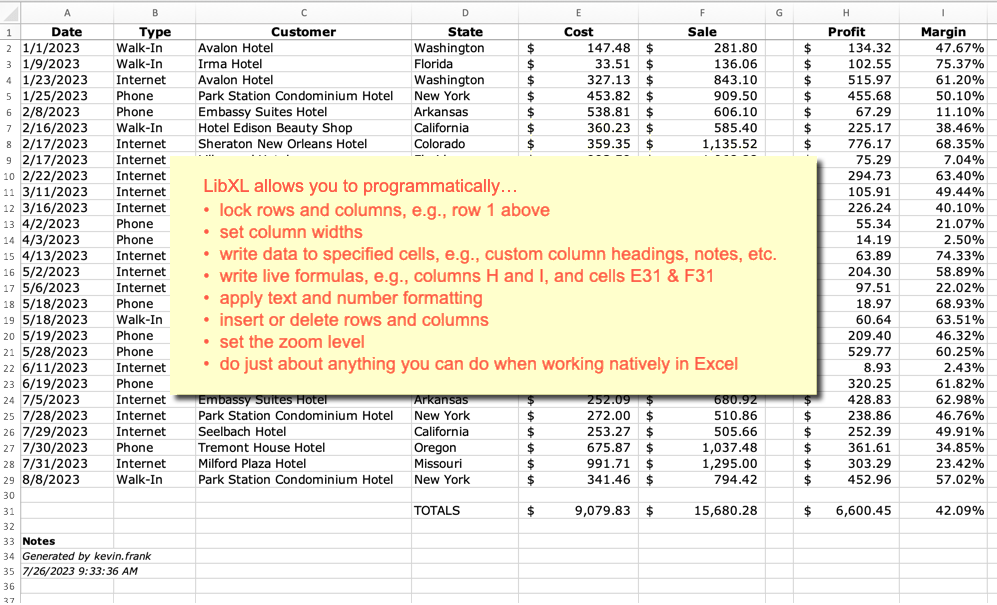
Today we’re going to look at producing spreadsheet output via LibXL, with help from a plug-in. Why bother? Several benefits immediately come to mind, including… power and flexibility, ease of implementation, and not having to add helper fields, tables, etc., to your database schema. With a plug-in you will typically do all the work at the script level, and generate feature-rich spreadsheets that otherwise would be difficult or impossible to produce from within FileMaker.


Demo file: Generating-Spreadsheets-with-LibXL.zip
(requires FM 19.5 or later)
Goya FMXL plug-in: https://goya.com.au/excel-plugin-for-filemaker
This plug-in is required for the demo to function. If unregistered it will add a trial notice banner at the top of the spreadsheet.
Note: if you are a Monkeybread user, MBS also offers an add-on plug-in for LibXL. The function calls are similar in both, and if you’re so inclined today’s demo file can be adapted to work with the MBS version. See documentation here, which can be helpful when using the Goya plug-in as well.