Update 30 September 2023: Free end point no longer available for this service. See JSON Currency Exchange Rates, v3 for a revised, functioning demo.
Introduction
This is a follow up to a behavior I mentioned last month where FileMaker’s JSON functions can transform a number into scientific notation when you might prefer to have that number remain in standard notation.
The overall functionality of the demo was covered last time. This time we’re going to focus on working around the behavior, followed by some related observations… but first let’s review. Continue reading “JSON – Force Standard Notation”→
Today we’re going to take a fresh look at pulling currency exchange rates into FileMaker, and this article is directly based on its predecessor. Why the re-visitation? Two reasons actually:
The “free” endpoints I relied on back in 2020 (and in 2021 when I revised the original demo) have been monetized, and apart from any cost considerations, I want this demo to work out of the box without requiring an API token.
The check box set I used for symbol selection last time was designed to accommodate a fixed and relatively small number of entries. That was a short-sighted decision that could not possibly scale gracefully. This time around I’m using an approach that will automatically accommodate any number of symbols.
About the author: Beverly Voth has been in the Claris FileMaker community many years. In addition to FileMaker Pro and its integrated products, she is a Full Stack Web developer & SQL database administrator. The only recipient of the FileMaker Excellence Award for Outstanding Contribution to the FileMaker Web Publishing Community (DevCon 2003), she’s been advocating Claris FileMaker and web since they could work together.
This article covers more Views, a little errata from past articles (Parts 1, 2, & 3), and where we go from here. This is the final article of the planned four. But if something really inspiring materializes, there may be followup article(s). Some famous “trilogies” (films and books, especially) have gotten additional content, so why not?
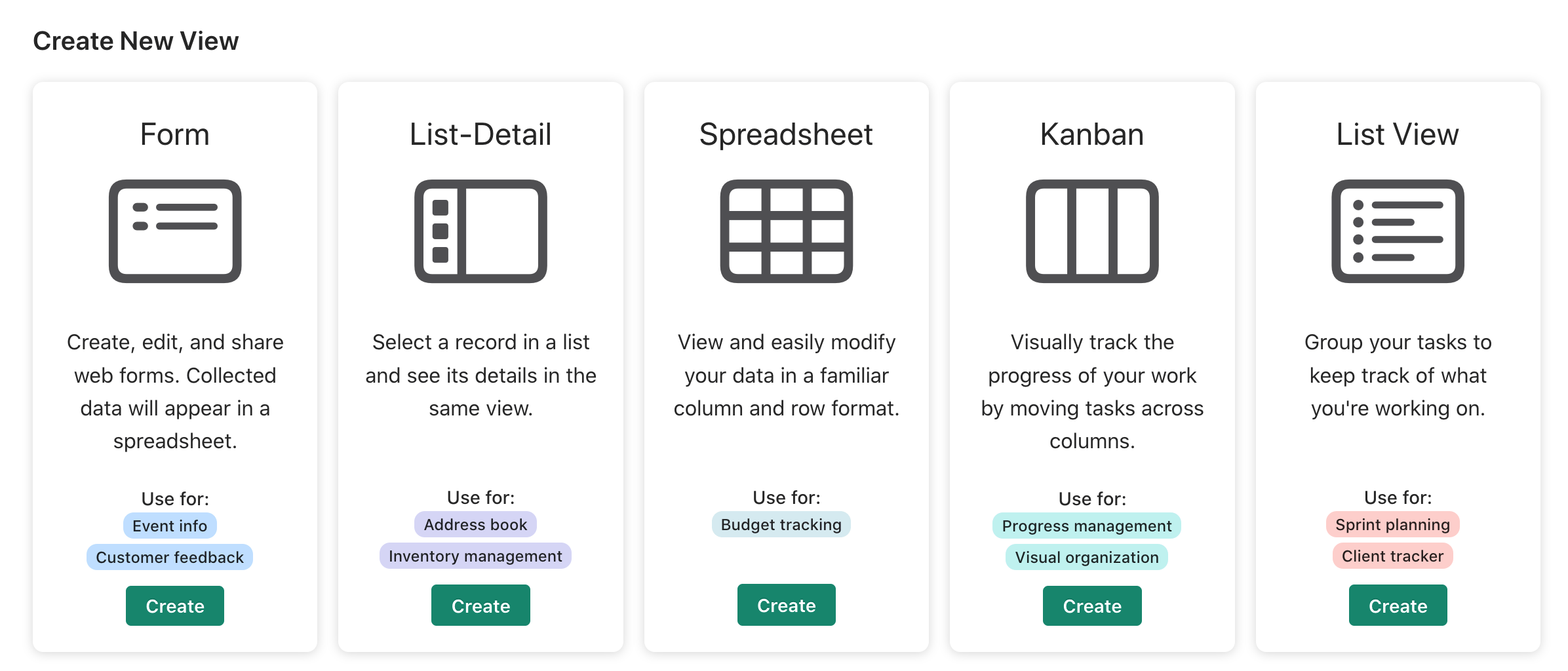
Welcome back! The Spreadsheet View and the Dashboard View are not the only features of Claris Studio. I chose them to discuss first because the Spreadsheet has more information about the tables and fields. That information may be helpful on all Views. But we have other Views: anonymous Form submission, a List-Detail View (suitable for searching, adding, editing), a Kanban View (just another way to present the data & edit it), and some new ones since the last article. Remember that Dashboards are created from the Spreadsheet View only, so they do not appear on this graphic:
Click on the Create New View button to see these options.
We can start with one of these views to create the “table” or we can start with existing data (from a Spreadsheet setup or migrated from Claris Pro). Let’s get started with a review of the Forms. Continue reading “Claris Studio (part 4): Forms the easy way!”→
Recently a client asked me to implement a virtual list reporting framework similar to the one I wrote about a few years ago in Virtual List Simplified. I added the framework to the client’s hosted file, and things went smoothly until I ran a report similar to the one shown below… and observed that the repeating summary field at the bottom wasn’t rendering. The same report worked flawlessly a) offline, and b) when hosted on FMS 19.4 and earlier, but when hosted via FMS 19.5 or 19.6, the summary repeater was malfunctioning.
About the author: Beverly Voth has been in the Claris FileMaker community many years. In addition to FileMaker Pro and its integrated products, she is a Full Stack Web developer & SQL database administrator. The only recipient of the FileMaker Excellence Award for Outstanding Contribution to the FileMaker Web Publishing Community (DevCon 2003), she’s been advocating Claris FileMaker and web since they could work together.
This is part three of a series on the new Claris platform. We introduced the overview, Claris Studio, Tell Me More! on 29 September 2022, and Claris Studio (part 2) – Integration with Claris Pro on 12 October 2022. This article gets into more details on the different types of views in Claris Studio. Since the spreadsheet view will likely be a most common usage for many, this article will be devoted to it. The spreadsheet view in Claris Studio has plenty of goodies & features, and can be used to create Dashboard views (charts and summary text).
A new spreadsheet view – with default fields, table name, & view name
Claris Studio, Spreadsheet View
Of all the views available in Claris Studio, the spreadsheet is a very flexible table for data entry & editing, sorting & grouping. These web-based data grids (tables) are more robust than FileMaker/Claris Pro table view, better than web viewer data tables (easier at least!), but probably not as full-featured as Excel or Numbers spreadsheets. There are no “cell” formulas or references as in some spreadsheets, but there is a way to present a grid of rows & columns for data entry, viewing, and reporting. Web-based data grids may use methods that allow drag-and-drop re-arrangement of rows and/or columns, as you will find in Claris Studio’s spreadsheet.
There are several JavaScript & CSS techniques & frameworks or libraries used for tables on the web. Many of them have been integrated into FileMaker Pro (and now Claris Pro) though Web Viewers.
But they all look like coding down and dirty. That’s great if that’s what you want to do. Would you like something easier? Would you like to send this data to the other Claris Studio view types, including dashboards (charting)? And would you like to share the data collected with Claris Pro? Let’s get started with the finer points of spreadsheets in Claris Studio! Continue reading “Claris Studio (part 3) – Spreadsheet: Details, please!”→
About the author: Beverly Voth has been in the Claris FileMaker community many years. In addition to FileMaker Pro & its integrated products, she is a Full Stack Web developer & SQL database administrator. The only recipient of the FileMaker Excellence Award for Outstanding Contribution to the FileMaker Web Publishing Community (DevCon 2003), she’s been advocating Claris FileMaker and web since they could work together.
Welcome back to part two of our Claris Studio & Claris Pro exploration. This article will cover Claris Pro and how it integrates with Claris Studio. Since we started with Claris Studio, Tell Me More!, there was a major update to the features in Claris Studio. You were advised to be alert! Check What’s New for the latest Claris Studio updates. This article is about conversion of Claris FileMaker Pro database files to Claris Pro files and how Claris Pro works with Claris Studio tables (two way interaction!)
What is Claris Pro?
Claris Pro is an application toolbox full of features that allow you to create user interfaces for data collection, display, and reporting. It can be used to create everything from a collection of Grandma’s recipes to full mission-critical business applications. It’s a cool and R.A.D. (pun intended!) toolbox for use by those starting out to full-stack relational database developers. Claris Pro uses a graphical interface for most creation, but easily works with external data exchanges. Once created with Claris Pro, these apps can be used on iPhones, iPads, or viewed in web browsers, as well as on the desktop/laptop by one user or thousands of users. You can use Claris Pro with Windows and macOS. Continue reading “Claris Studio (part 2) – Integration with Claris Pro”→
About the author: Beverly Voth has been in the Claris FileMaker community many years. In addition to FileMaker Pro & its integrated products, she is a Full Stack Web developer & SQL database administrator. The only recipient of the FileMaker Excellence Award for Outstanding Contribution to the FileMaker Web Publishing Community (DevCon 2003), she’s been advocating Claris FileMaker and web since they could work together.
This is the first in a series of articles exploring portions of the new Claris Platform. Launched in September 2022, this is just the beginning of the journey! Curious souls that we are, many question arise, and these articles are meant to supplement what we’ve seen so far, and perhaps give some different perspectives, along with plenty of screen shots. Concentration in these articles will be on Claris Studio and its relationship with Claris Pro.
Disclaimer: This platform may have rapid changes and this article may not be current after it is published. Always check for the latest information & videos.
What is Claris Studio?
Claris Studio is a cloud-based (access through a web browser) editor and data browser. A Claris ID is used to login and teams can be invited to join (by Claris ID). Access to view or edit can be constrained by inviting team members to Hubs with shared Views. The editor can create: Forms, Spreadsheets (tables), List-Detail Views, Dashboards (with charts and summary data), and Kanban Views. Some basic Views are preset for you to use as examples when you first start. There are many tooltip hints and popover & other dialogs to assist you along the way.
Today we have some custom functions (CFs) that can help you accomplish various JSON-related tasks in FileMaker. Back in 2018 I had this to say about JSON custom functions…
My inclination is to really understand something before I use a custom function to simplify things, but that’s a matter of personal choice… and one which can vary depending on the situation.
And four years later I find myself using JSON custom functions on a daily basis, to save time and to boost productivity — for example, to merge two objects into a single object, or to deduplicate an array.
Note: where appropriate, some of today’s custom functions utilize bracket notation to avoid unexpected results when and if key names contain wonky characters such as dots, brackets or braces. You can read more about bracket notation in Thinking About JSON, part 4.
Update: Make sure to read Tony White’s comment below. It contains important additional information re: the behavior described in this article.
Recently I noticed some code that had worked flawlessly for years was suddenly returning “?” instead of valid values. What it came down to was that I had renamed my file from “JSON Custom Functions” to “JSON Custom Functions for FM 19.5”
Well you know those functions like ValueListItems…
ValueListItems ( fileName ; valueListName )
…that have a fileName argument? The culprit turned out to be that I was using Get(FileName) for that argument, and I needed to instead use "".
All 21 of the design functions are vulnerable to this, ahem, behavior. From the online help —
If you specify a filename that contains a period, include the filename extension in the parameter. Otherwise, functions may interpret the period in the filename as the beginning of the filename extension, which can lead to unexpected results.
If you specify no filename (""), functions return results for the current file.
Bottom line: When using a design function and referencing the current file, use "" instead of Get(FileName). There’s no down side, and your code won’t break if you decide to add a period to the file name.